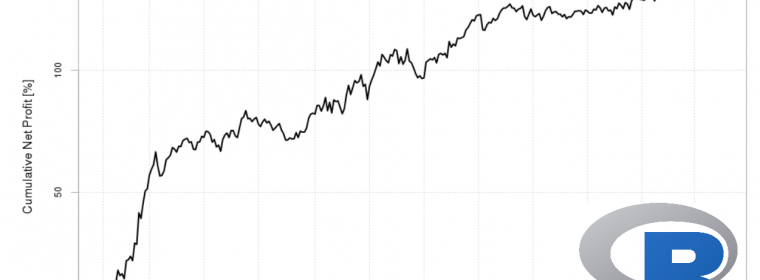
As a data scientist, whenever I am developing and testing financial models in R I’ve consistently run into data size limitations, large or distributed compute clusters, and many long waits for my results to be processed and returned. That’s why I was genuinely impressed with how our recently released docker image of Pivot Billions, […] continue reading »
Blazing Fast Financial Backtesting from R