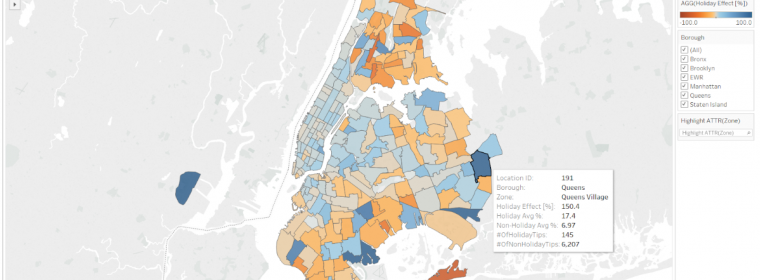
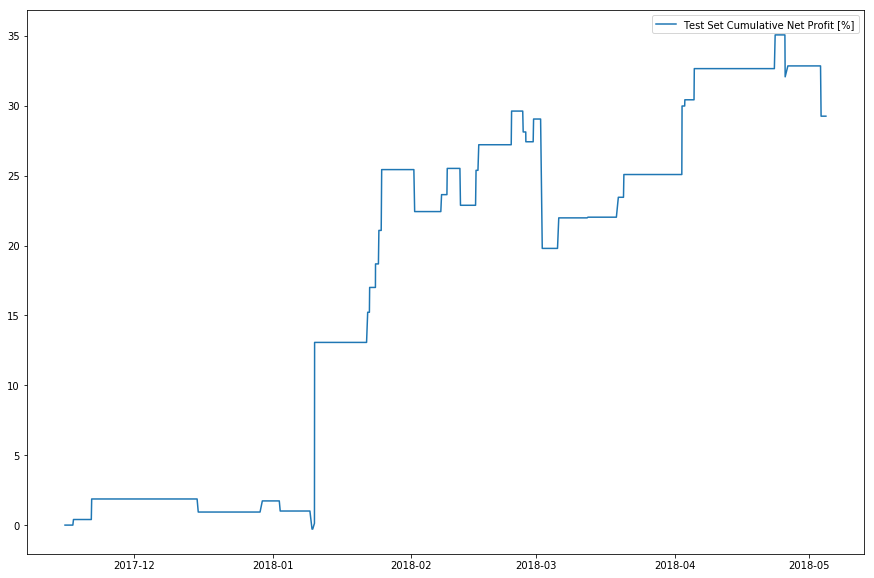
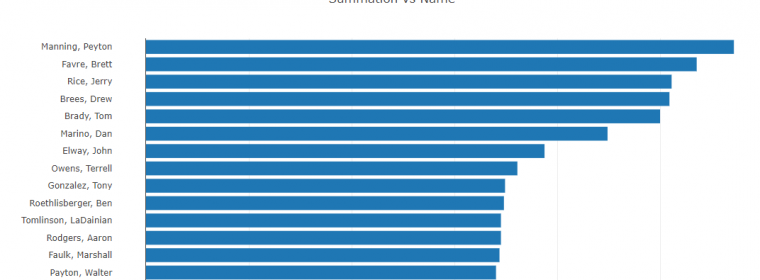
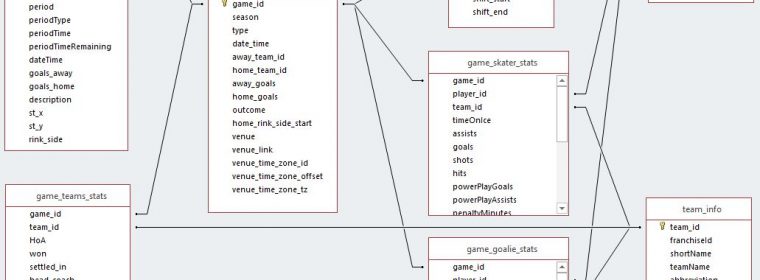
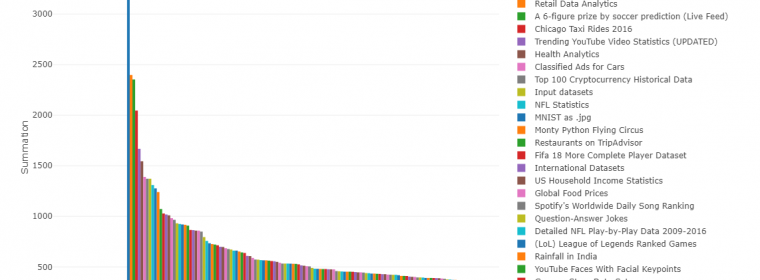
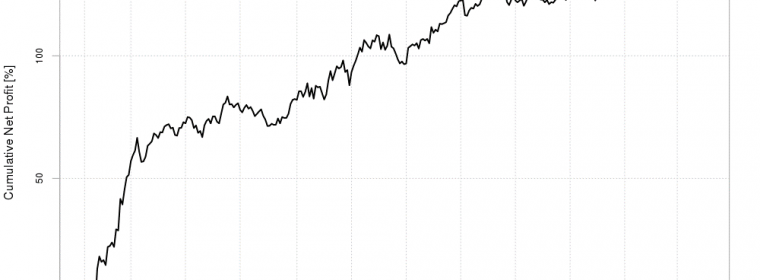
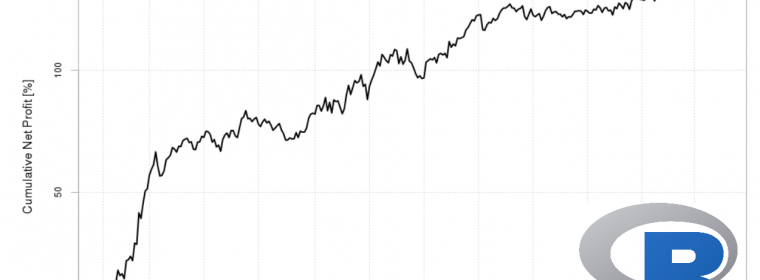
The age of data has arrived. With it, more and more datasets are created and they just keep getting bigger. Whether dealing with private or open data, individuals and organizations across the world are realizing that there are enormous amounts of information and insights to be gained from massive data. The public NYC Taxi and […] continue reading »
Taming 1.5 Billion Rows of “Big Apple” Data